
AWS Data Pipeline: This is a web service that has access to the data from various services. It analyzes and processes the information at the same place. It then keeps information to various AWS services like Amazon S3, DynamoDB, etc.
For instance, utilizing data pipeline, one will archive web server logs to Amazon S3 bucket on an everyday basis & then run EMR cluster on the logs which generate the reports weekly.
AWS Data Pipeline Concept
AWS Data Pipeline concept is very easy. We have a Data Pipeline remaining at the top. We’ve input stores that can be Amazon S3, Redshift, or Dynamo DB. Information from the input stores is transferred to Data Pipeline. Moreover, Data Pipeline examines, processes information & then the outcomes are sent to output stores. The output stores can be Redshift, Amazon S3, or Amazon Redshift.
AWS Data Pipeline benefits
- Distributed
It’s made on Distributed & reliable infrastructure. When a fault happens inactivity as Data Pipeline is created, the service of AWS Data Pipeline will retry activity.
- Simple to use
AWS Data Pipeline is easy to create. This is because an AWS offers a drag & drop console, i.e., one doesn’t have to compose business logic to make a data pipeline.
- Transparent
AWS Data Pipeline provides complete control over computational resources like EMR reports or EC2 instances.
- Flexible
AWS Data Pipeline supports numerous features like scheduling, error handling & dependency tracking. Data Pipeline does various actions like executing SQL Queries on databases, running Amazon EMR tasks, or executing the custom apps running on EC2 instances.
- Scalable
Through using Data Pipeline, one can dispatch the task to one or numerous machines successively or parallels.
- Low-cost
AWS Data Pipeline is cheap to use, & it’s built with little monthly rate.
AWS Data Pipeline Components
The following are the major parts of the AWS Data Pipeline:
- Pipeline Definition
This specifies the way business logic needs to communicate with Data Pipeline. It consists of various data:
- Preconditions
Preconditions need to be content before scheduling an activity. For instance, when one needs to move the information from Amazon S3, its precondition is to view whether the information is available at Amazon S3 or it’s not. If a precondition is approved, then the activity will be executed.
- Activities
These are actions that do the SQL Queries at the databases, transform the information from a single data source to a different data source.
- Actions
This updates your pipeline status like sending an email to you or activates an alarm.
- Resources
You’ve computed resources like EMR cluster or Amazon EC2
- Data Nodes
This specifies the location, name & data sources format like Dynamo DB, Amazon S3, etc.
- Schedules
Scheduling is done at the Activities.
- Pipeline
This consists of 3 important items:
- Attempts
Data Pipeline enables one to retry the unsuccessful operations. These are known as Attempts.
- Instances
When every pipeline part is assembled into a pipeline and it makes an actionable instance that contains information of some precise task.
- Pipeline components
This is the way you communicate the Data Pipeline to AWS services.
- Task Runner
This is an application that polls tasks from Data Pipeline & does the tasks.
Task Runner Architecture
Task Runner polls tasks from Data Pipeline. The Task Runner reports the progress immediately after the job is done. After the report is made the state is checked if the task has succeeded or not. If the task succeeds, then it ends & if not, the retry attempts are checked. If retry attempts are remaining, then the entire process carries on again; else the task will end abruptly.
Making Data Pipeline
- Sign in to AWS Management Console.
- Create Dynamo DB-table & two S3-buckets.
- Create Dynamo DB-table. Click at creating a table.
Fill in the details like table name, Primary key to make a new table.

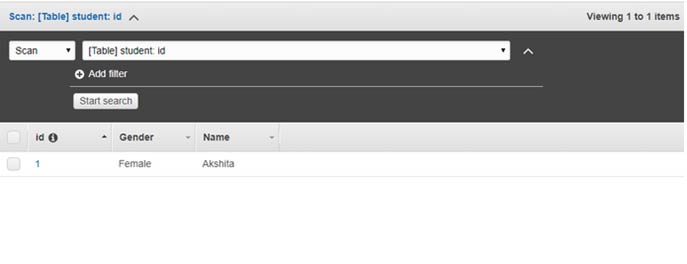
The image below shows that table “student” is created.

Click on items & then click create an item.
We need to add 3 items which include id, Name, & Gender.
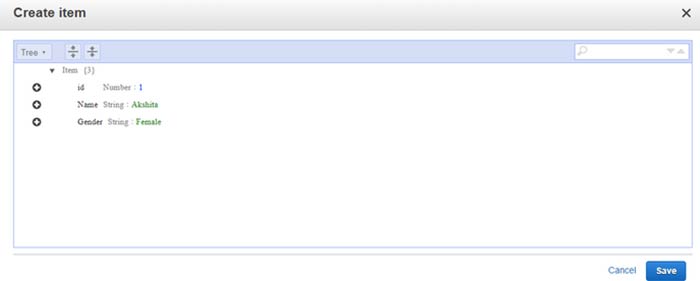
The image below shows a screen in which data is put in a DynamoDB table.
After that, we need to create 2 S3-buckets. The first will keep information that we’re exporting from DynamoDB & the second will keep the logs.
We’ve created 2 buckets, i.e., studata & logstoredata. logstoredata bucket keeps the logs and the studata bucket keeps the information that we’re exporting from DynamoDB.

After creating Data Pipeline. Go to the data Pipeline service & then click on Get started key.

Fill in the details to make a pipeline, & then click on Edit on Architect if you need to change a part in a pipeline.



The image below appears when you click on Edit in Architect. You will view a warning occurring, that is TerminateAfter is missing. Removing this warning, one is required to add a new TerminateAfter field in Resources. After the field is added, click on Activate Button.
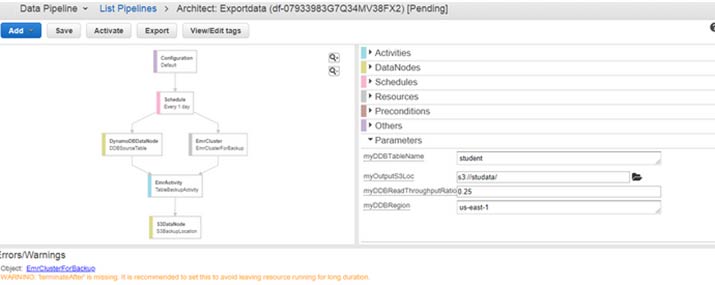
Firstly, the WAITING_FOR_DEPENDENCIES status pops up. When refreshing is made, the status gets to WAITING_FOR_RUNNER. When the Running state pops up, you can view your S3 bucket, the information will be kept there.
